How to process nested arrays in json with Athena


Suppose you are writing an application for a library. Instead of storing book inventory in traditional db, you decided to use s3. Each book record is converted to json, stringified, written to a file and stored in S3 as an object. To read this, you create tables in Athena and write SQL queries to fetch the data.
{
'name':'my-book-name',
'ISBN':123456,
'publisher':'the-one',
'publication-date':'', ...
}
| Name | ISBN | Publisher | Publication-date |
| my-book1 | 123456 | the-one | 1-1-2020 |
But you realized that the JSON is not a flat structure. It consist of nested objects.
{
'name':'my-book-name',
'ISBN':123456,
'publisher':'the-one',
'publication-date':'',
'authors':[
{'id':1,'name':'author-1'},
{'id':2,'name':'author-2'}
]
}
You can't store this JSON in a simple table because field 'authors' contains an array of objects and you can not directly query author id and author name.
There are two problems with authors field.
It is an array.
Each item in array is an object having multiple properties.
To solve the first problem, we need to flatten the array into multiple rows. For the given record, after flattening, it would create two records since there are two authors for the book.
{
'name':'my-book-name',
'ISBN':123456,
'publisher':'the-one',
'publication-date':'',
'author':{'id':1,'name':'author-1'}
},
{
'name':'my-book-name',
'ISBN':123456,
'publisher':'the-one',
'publication-date':'',
'author':{'id':2,'name':'author-2'}
}
For 2nd problem, once we have converted array in multiple rows, we can access individual property from each row (author).
To convert authors array in multiple records, we don't need to change the way we store data although you can split book JSON into two and move authors into a separate JSON. But here we are keeping the base data as it is and creating the view on top of it which gives us access to author object and its properties.
This is the table which contains the data in JSON without any change.
| Name | ISBN | publisher | publication-date | Authors |
| my-book1 | 123456 | the-one | 1-1-2020 | [{'id':1,'name':'author-1'},{'id':2,'name':'author-2'}] |
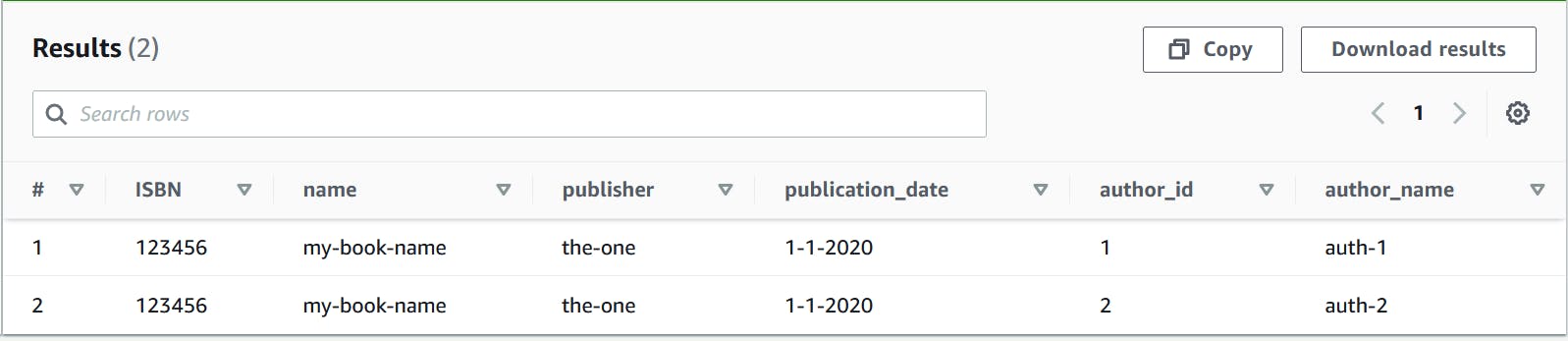
What we want is a view on top of this that provides all the fields.
| Name | ISBN | publisher | publication-date | Author-id | author-name |
| my-book1 | 123456 | the-one | 1-1-2020 | 1 | author-1 |
| my-book1 | 123456 | the-one | 1-1-2020 | 2 | author-2 |
To achieve this, we can use UNNEST function which converts an array to multiple rows.
a simple Athena query to create a view -
CREATE OR REPLACE VIEW vBook AS
#[1]
WITH dataset as (
SELECT '123456' as ISBN, 'my-book-name' as name, 'the-one' as publisher, '1-1-2020' as publication_date,
JSON '[{"id":"1","name":"auth-1"},{"id":"2","name":"auth-2"}]' as authors )
#[2]
SELECT ISBN,name,publisher,publication_date,author['id'] as author_id,author['name'] as author_name from (
#[3]
SELECT ISBN,name,publisher,publication_date,CAST(authors as ARRAY(MAP(varchar,varchar))) as authors from dataset)
CROSS JOIN UNNEST(authors) as t(author)
[1]First we fetch the data from *table *as per the criteria and storing in dataset. Don't get confused here since we have hard coded the data here . This is just to simulate availability of some records.
[3]Now in the internal select statement, we select all the columns we need and also convert JSON to an array of map.
[2]this is the final select statement where we UNNEST the authors(array) as author and select fields required.
Now you can run your query on this view
SELECT * from vBook
This is one of the solution to handle nested json and not the only solution. You should always check the data size, partition, performance and decide on the the solution.
happy coding ...