Apache Airflow 101...

It is very common to work on data pipeline or workflow in the area of batch processing /data engineering. In that case, Apache airflow can make the job easier.
Apache airflow is a tool to create, manage and run workflows. It helps to build a workflow by combining individual tasks and manage their dependencies. These tasks can be run locally or on a multi-node cluster using Kubernetes / Celery. And there is also a web UI to manage these workflows.
The workflow, that we create, is in the form of a python module where we specify the tasks, their order and how these tasks should be run. This workflow is called DAG (Directed acyclic graph) . Each node in this graph is a task. We would be using dag and workflow interchangeably.
Here is a sample dag which has two tasks , start_task and end_task. In this example, these tasks are dummy tasks but these could be anything. We have also set the order of these tasks. First start_task will run and post that end_task. This is a perfectly deployable dag although it doesn't do any thing.
This is what a dag/workflow looks like. of course, it won't be that simple for a real world production application but concept remains same.
Airflow provides a bunch of inbuilt tasks which you can directly use in your workflow. Like, executing a sql query on a database, checking if a file exist etc. In a real world application, this is not enough and we would need the support to write these tasks as and when required. This is available and can be done simply by writing a function and decorating it with task decorator.
This is a task which creates a file and writes to it, not very useful but just to give an idea. File containing definition of dag and tasks is our workflow and can be deployed.
Now, lets talk about how these workflows are run.
Airflow consists of a scheduler and executor. We deploy the workflow on a scheduler. Scheduler runs task on executor as per the configuration. Executor is the component which does the actual work and could run locally or on a cluster. We need to deploy DAG/Workflow to airflow/dags folder on the scheduler. Once deployed, DAG / workflow will be available in some time for running and can be viewed in web UI.
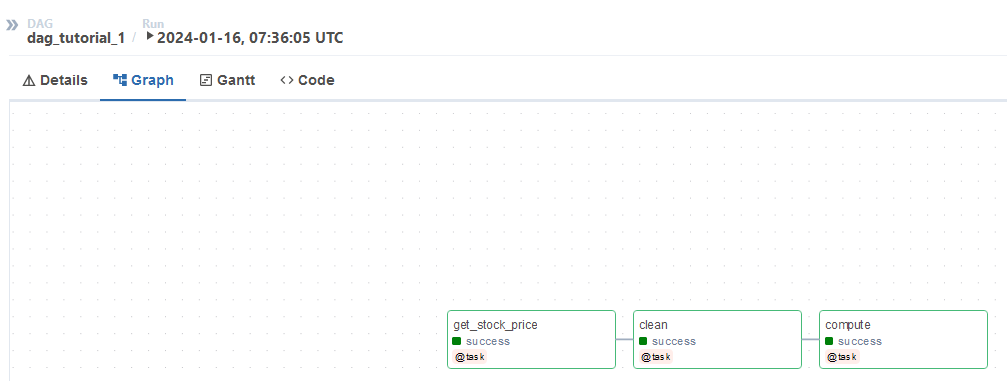
Let's build a workflow which downloads market data for a number of stocks, cleans it and calculates correlation among those stocks. As final output, it saves computed data in a given path.
We can divide this workflow in 3 individual tasks.
Download data
Data cleaning
Compute correlation
airflow1.py has a few helper methods to perform download, cleaning and compute. Note that these are regular python function.
dag1.py is our dag which contains the task required in the workflow.
dag is a python function annotated with dag decorator.
Each task is another function defined within dag and annotated with task decorator.
We call these tasked in the order these are required to be executed. We can also pass return value from one task to another task in the pipeline. Airflow behind the scene handles this cross communication. Note that when these tasks are running, these are running in different context/process.
Last step is to call the dag.
We need to deploy dag1.py in airflow/dags folder on the scheduler. Since this dag is importing airflow1.py, make sure this is available in PYTHONPATH (otherwise it may throw exception that this module is not available)
Once this is deployed, it will be visible on the web UI in a few minutes. You can trigger it from here .

If there are no errors, it will run successfully. You can also see the status from the web UI.
This is a high level overview of airflow just to give some idea. Airflow's documentation is a good place to start.
Thanks for reading.


